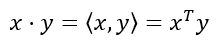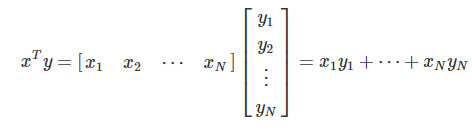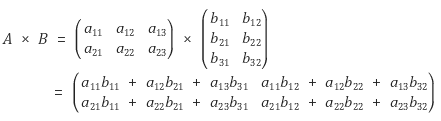6.1.4 모멘텀


v라는 새로운 변수가 있는데 이는 물리에서의 velocity에 해당한다. 위의 식 (v ← ...)은 기울기 방향으로 힘을 받아 물체가 가속되는 물리 법칙을 나타낸다. 모멘텀은 그림과 같이 공이 그릇의 바닥을 구르는 듯한 움직임을 보여준다.
#솔직히 말해서, 모멘텀 (운동량)과 속도에 대한 물리식들을 살펴보았지만 연관성을 잘 모르겠다.

αv항은 물체가 아무런 힘을 받지 않을 때 서서히 하강시키는 역할을 한다.
class Momentum:
"""모멘텀 SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum*self.v[key] - self.lr*grads[key]
params[key] += self.v[key]momentum이 α 에 해당한다. v는 초기화 때는 아무 값도 담지 않고, 대신 update()가 처음 호출될 때 매개변수와 같은 구조의 데이터를 딕셔너리 변수로 저장한다.
##for key, val in params.items():
self.v[key] = np.zeros_like(val) 이 부분에 대한 설명으로 새로운 게시글 링크를 남긴다.
https://codingneedsinsanity.tistory.com/30

모멘텀의 갱신 경로는 공이 구르듯 움직인다. 굉장히 직관적인 표현을 쓰자면 'SGD에 비해서 지그재그 정도가 적다'
정리하자면
- x축의 힘은 아주 작지만 방향은 변하지 않아 한 방향으로 일정하게 가속
- y축의 힘은 크지만 위아래로 번갈아 가며 상충하여 속도는 안정적이지 않음
- SGD보다 x축 방향으로 빠르게 다가가 지그재그 움직임이 적음
6.1.5 AdaGrad
신경망 학습에서는 학습률(η)값이 중요하다. 값이 작으면 학습 시간이 너무 길어지고, 너무 크면 발산하여 학습이 제대로 이루어지지 않는다.
이 학습률을 정하는 효과적 기술로 학습률 감소(learning rate decay)가 있다. 학습을 진행하면서 학습률 자체를 점차 줄여나가는 방법이다. 학습률을 서서히 낮추는 가장 간단한 방법은 매개변수 '전체'의 학습률 값을 일괄적으로 낮추는 것이다. 이를 더욱 발전시킨 것이 AdaGrad이다. AdaGrad는 '각각의 ' 매개변수에 '맞춤형'값을 만들어준다.
AdaGrad는 개별 매개변수에 적응적으로 학습률을 조정하면서 학습을 진행한다.


h는 기존 기울기값을 제곱하여 계속 더해준다. (⊙기호는 행렬의 원소별 곱셈을 의미) 그리고 매개변수를 갱신할 때 sqrt(h)의 역수값을 곱해 학습률을 조정한다. 매개변수의 원소 중에서 크게 갱신된 원소의 학습률이 낮아진다는 뜻인데, 학습률 감소가 매개변수의 원소마다 다르게 적용됨을 뜻한다.
##AdaGrad는 학습을 진행할수록 갱신 강도가 약해져, 어느 순간 갱신량이 0이 되어 전혀 갱신되지 않는다. 이 문제를 해결하기 위해서 RMSProp이라는 방법이 있는데, 이는 먼 과거의 기울기는 잊고, 새로운 기울기 정보를 크게 반영하는 식이다. 이를 지수이동평균 (Exponential Moving Average, EMA)이라 하여, 과거 기울기 반영 규모를 기하급수적으로 감소시킨다.
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key]=np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key]*grads[key]
params[key] -= self.lr*grads[key]/(np.sqrt(self.h[key])+1e-7)** 마지막에 1e-7이 들어가는 이유는 divide by zero를 막기 위함이다.

처음에 설명한 것처럼, 초기에는 크게 움직이고 점점 갱신 정도가 작아지는 것을 확인할 수 있다.
6.1.6 Adam
Adam은 위 모멘텀과 AdaGrad의 두 기법을 융합한 것이다. 이론은 복잡하지만 직관적으로는 이 둘을 융합한 모습이다. 매개변수 공간을 효율적으로 탐색해주고, 하이퍼파라미터의 '편향 보정'이 진행된다. 책에 서술된대로 여기서 설명을 마치고 자세한 내용은 다음 링크에 남긴다.
https://medium.com/@nishantnikhil/adam-optimizer-notes-ddac4fd7218
Everything you need to know about Adam Optimizer
Paper : Adam: A Method for Stochastic Optimization
medium.com

6.1.7 어느 갱신 방법을 이용할 것인가?

그림만 봐서는 AdaGrad가 가장 좋은 것 같지만, 결론만 이야기하면 아니다. 각 방법이 각각 장단이 있어 잘 푸는 문제가 있고 아닌 문제가 있다. 책에서는 요즘에는 많은 사람들이 Adam을 사용한다고 한다. (2017년 기준) (위 교재에서는 Adam과 SGD를 사용한다.)
6.1.8 MNIST 데이터셋으로 본 갱신 방법 비교

위 실험에서는 각 층이 100개의 뉴런으로 구성된 5층 신경망에서 ReLU를 활성화 함수로 사용해 측정했다.
일반적으로 SGD보다 다른 세 기법이 빠르게 학습하고, 때로는 최종 정확도 역시 높게 나타난다고 한다.
'머신 러닝 및 파이썬 > 밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| Ch.6 학습 관련 기술들/ 6.3 배치 정규화 (0) | 2020.03.11 |
|---|---|
| Ch.6 학습 관련 기술들/ 6.2 가중치의 초기값 (0) | 2020.03.11 |
| Ch.6 학습 관련 기술들/ 6.2 확률적 경사 하강법 (0) | 2020.03.10 |
| Ch.5 오차역전파법/ 5.6 Affine/Softmax 계층 구현 (0) | 2020.03.05 |
| Ch.5 오차역전파법/ 5.5 활성화 함수 계층 구현 (ReLU, Sigmoid) (0) | 2020.03.03 |