4.3.1 미분

과외를 하며 수없이 가르쳤던 미분이다... 미분은 다른 말로 순간변화율을 의미한다.
이 것을 파이썬 코드로 그대로 옮긴다면 참 좋겠지만... 문제점이 있다.
1. 0에 가까운 수를 어떻게 표현할까
2. 0에 가까운 수 (ex. 10e-50) 를 사용하면 반올림 오차로 인해 0.0이 되버림
그렇기에 예시보다는 큰 수를 사용해야한다. 또한 서적에서는 전방 차분 (x+h와 x의 차이) 대신 중앙 차분 (x+h 와 x-h)를 이용한다. 코드로 옮기면 다음과 같다.
def numerical_diff(f, x):
h = 1e-4
return (f(x+h) - f(x-h)) / (2*h)
## f는 함수이다. 즉 함수가 인자로 사용되었다.
4.3.2 수치 미분의 예


실제 해석적 해 (고등학교 시절 배운 진짜 미분) 는 0.2와 0.3 이다. 이 정도면 그 오차가 굉장히 작다고 볼 수 있다.
여기에 대한 접선 (tangent line)을 그리는 코드와 결과를 보자
def tangent_line(f, x):
d = numerical_diff(f, x)
print(d)
y = f(x) - d*x
return lambda t: d*t + y
x = np.arange(0.0, 20.0, 0.1)
y = function_1(x)
plt.xlabel("x")
plt.ylabel("f(x)")
tf = tangent_line(function_1, 5)
y2 = tf(x)여기서 tangent_line의 return 값이 lambda형태로 나와있는데, 이는 return값으로 특정 함수를 만들어주기 위함이다.
t라는 변수를 받아 d*t + y 를 반환해준다. 결론적으로 보면 f'(a)(x-a) + f(a) 와 동일하다.
추후 lambda에 대해서 더 공부해야겠지만, 일단 그렇게 알아두자.

4.3.3 편미분
변수가 두 개 이상일 때, 하나를 상수 취급하고 미분하는 것을 편미분 이라고 한다.

구현하면
def function_2(x):
return x[0]**2 + x[1]**2
#또는 np.sum(x**2)##익숙해질 수 있도록 np.sum으로 만든 것도 사용해보자
4.4 기울기
x0, x1의 편미분을 동시에 계산하여 벡터로 정리한 것을 기울기 (gradient)라고 한다.
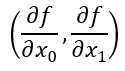
def numerical_gradient(f, x):
h = 1e-4
grad = np.zeros_like(x) #shape, dim 유지하지만 값은 0
for idx in range(x.size):
tmp_val = x[idx]
#f(x+h)
x[idx]=tmp_val + h
fxh1 = f(x)
#f(x-h)
x[idx]=tmp_val - h
fxh2 = f(x)
grad[idx]=(fxh1-fxh2)/(2*h)
x[idx] = tmp_val #값 복원
return grad결과를 보자
numerical_gradient(function_2, np.array([3.0,4.0]))
Out[168]: array([6., 8.])
numerical_gradient(function_2, np.array([0.0,2.0]))
Out[169]: array([0., 4.])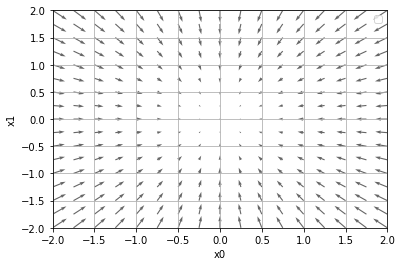
기울기가 가리키는 쪽은 각 장소에서 함수의 출력 값을 가장 크게 줄이는 방향이다. 책에서 굉장히 중요한 포인트라고 한다.
4.4.1 경사법(경사 하강법)
신경망은 학습 시에 최적의 매개변수를 찾아야한다. 즉 손실 함수가 최솟값이 될 때의 매개변수 값을 찾아야하는데, 이게 알아내기가 만만치 않다. 이런 상황에서 기울기를 잘 이용해 함수의 최솟값을 찾으려고 하는 것이 경사법이다.
##실제로 복잡한 함수에서는 경사법을 이용한다 하더라도, 실제로는 기울기가 0인 부분을 찾아나가는 것이기 때문에 최솟값이 아니라 극솟값이나 Saddle point를 구하게 되는 경우가 생길 수 있다.
경사법은 현 위치에서 기울어진 방향으로 일정 거리만큼 이동한다. 그 후에 다시 기울기를 구해, 기울어진 방향으로 나아가기를 반복한다. 이렇게 함수의 값을 점차 줄이는 것이 경사법(gradient method)이다.
##최솟값을 찾으면 경사 하강법, 최댓값을 찾으면 경사 상승법, 일반적으로는 경사 하강법을 많이 사용한다.
경사법을 수식으로 나타내면 다음과 같다.

여기서 η는 eta라고 부르며 갱신하는 양을 나타낸다. 이를 신경망 학습에서 학습률(learning rate)라고 한다.
한 번의 학습으로 얼마만큼 학습해야 할지, 즉 매개변수 값을 얼마나 갱신하는지를 정한다.
학습률은 특정 값으로 정해두어야한다. 신경망 학습에서는 보통 이 학습률값을 변경하면서 올바르게 학습하고 있는지 확인하면서 진행한다.
경사 하강법은 다음과 같이 간단한게 구현한다.
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return xinit_x는 초기값, lr은 learning rate
함수의 기울기를 구하고, 그 기울기에 학습률을 곱한 값으로 갱신하는 처리를 step_num번 반복한다.
init_x = np.array([-3.0,4.0])
gradient_descent(function_2, init_x=init_x, lr=0.1, step_num=100)
Out[187]: array([-6.11110793e-10, 8.14814391e-10])
init_x = np.array([-3.0,4.0])
gradient_descent(function_2, init_x=init_x, lr=10, step_num=100)
Out[188]: array([-2.58983747e+13, -1.29524862e+12])
init_x = np.array([-3.0,4.0])
gradient_descent(function_2, init_x=init_x, lr=1e-10, step_num=100)
Out[189]: array([-2.99999994, 3.99999992])lr을 적당하게 0.1로 세팅하였을 때는 (0,0)에 거의 근접한 값이 나온다. 하지만 lr을 다르게 세팅한 경우, 굉장한 오차가 발생했음을 알 수 있다.

4.4.2 신경망에서의 기울기
신경망 학습에서도 기울기를 구해야 한다. 이는 가중치 매개변수에 대한 손실 함수의 기울기이다.
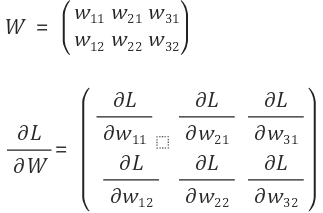
책에 있는 코드를 보자
class simpleNet:
def __init__(self):
self.W = np.random.randn(2,3) # 정규분포로 초기화
#randn은 가우시안 분포로 랜덤값 부여
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y, t)
return loss여기서 W는 가중치 매개변수를 의미한다. 일단은 가우시안 꼴로 랜덤한 값을 부여했다.
>>>net = simpleNet()
>>>print(net.W)
[[ 0.11633986 0.10927077 -0.93392791]
[-1.67889742 2.13145596 -0.33077693]]
>>>x=np.array([0.6,0.9])
>>>p=net.predict(x)
>>>print(x)
array([-1.44120377, 1.98387283, -0.85805598])
>>>np.argmax(p)
1
>>>t=np.array([0,0,1])
>>>net.loss(x, t)
2.9288931975720534이제 여기서 기울기를 구해보자. 앞서 사용한 numerical_gradient(f, x)를 사용할 것이다.
>>>def f(w):
return net.loss(x, t)
>>>dW = numerical_gradient(f, net.W)
>>>print(dW)
[[ 0.01790151 0.55002379 -0.5679253 ]
[ 0.02685226 0.82503568 -0.85188794]]이렇게 결과 역시 2X3의 행렬이 나오는 것을 알 수 있다. 해석하자면 다음과 같다.
dW의 w11은 약 0.8이다. 이는 w11을 h만큼 늘리면 손실 함수의 값이 0.8h만큼 증가한다는 의미이다. 즉 손실 함수를 줄인다는 관점으로 접근하면, w11은 음의 방향으로 갱신해야 함을 알 수 있다.
'머신 러닝 및 파이썬 > 밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| Ch.4 신경망 학습/ 4.5 학습 알고리즘 구현하기 (0) | 2020.03.03 |
|---|---|
| Python: Lambda 식 (0) | 2020.03.02 |
| Ch.4 신경망 학습/ 4.2 손실함수 (0) | 2020.02.26 |
| Ch.4 신경망 학습/ 4.1 데이터 주도학습 (0) | 2020.02.24 |
| Ch.3 신경망/ 3.5 출력층 설계하기 (0) | 2020.02.23 |