위 자료는 SungKim 교수의 PyTorch Zero To All 강의의 내용입니다.
이전까지는 1개의 hidden layer를 가진, 모델들을 보았으나, 위 모델은 mulit-layer입니다.
from torch import nn, optim, from_numpy
import numpy as np
xy = np.loadtxt('./data/diabetes.csv.gz', delimiter=',', dtype=np.float32)
x_data = from_numpy(xy[:, 0:-1])
y_data = from_numpy(xy[:, [-1]])
print(f'X\'s shape: {x_data.shape} | Y\'s shape: {y_data.shape}')먼저 주어진 데이터를 numpy로 불러오고, tensor로 변환해줍니다.
데이터는 input 성분이 8개, output이 1개이며, 전체 데이터수는 759개입니다.
input-> 8행, output -> 1행
output은 0과 1 즉, 당뇨로 진단 혹은 아님 두 가지의 logistic입니다.
class Model(nn.Module):
def __init__(self):
"""
In the constructor we instantiate two nn.Linear module
"""
super(Model, self).__init__()
self.l1 = nn.Linear(8, 6)
self.l2 = nn.Linear(6, 4)
self.l3 = nn.Linear(4, 1)
self.sigmoid = nn.Sigmoid()
self.relu = nn.ReLU()
def forward(self, x):
"""
In the forward function we accept a Variable of input data and we must return
a Variable of output data. We can use Modules defined in the constructor as
well as arbitrary operators on Variables.
"""
#out1 = self.sigmoid(self.l1(x))
#out2 = self.sigmoid(self.l2(out1))
out1 = self.relu(self.l1(x))
out2 = self.relu(self.l2(out1))
y_pred = self.sigmoid(self.l3(out2))
return y_pred모델은 다음과 같이 되었있습니다.
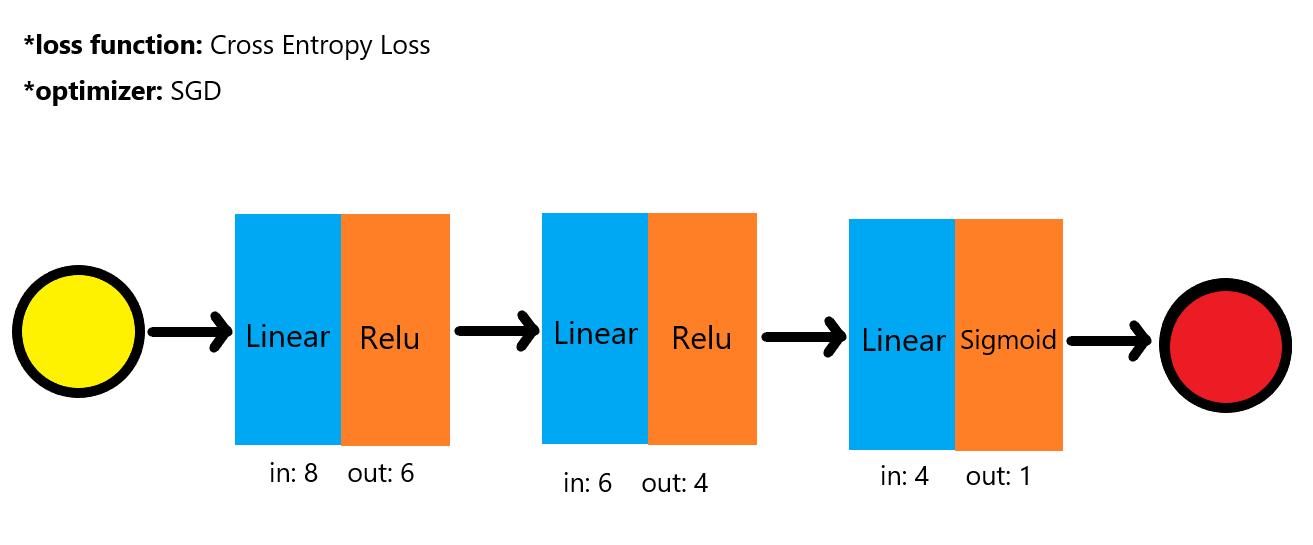
원본 코드에는 첫 번째, 두 번째 레이어의 Activaition function이 Sigmoid였으나, 정확도가 ReLU에 비해서 너무 낮아서 ReLU라고 바꿔보았습니다.
model = Model()
criterion = nn.BCELoss(reduction='mean')
optimizer = optim.SGD(model.parameters(), lr=0.1)
# Training loop
iter_num = 100
for epoch in range(iter_num):
# Forward pass: Compute predicted y by passing x to the model
y_pred = model(x_data)
# Compute and print loss
loss = criterion(y_pred, y_data)
print(f'Epoch: {epoch + 1}/{iter_num} | Loss: {loss.item():.4f}')
# Zero gradients, perform a backward pass, and update the weights.
optimizer.zero_grad()
loss.backward()
optimizer.step()다음과 같이 학습하였습니다.
BCEloss의 경우, 마지막 레이어의 값이 0~1로 조정해주어야 하기 때문에 sigmoid를 적용하였습니다.
[고민해볼 점]
왜 Sigmoid 보다 ReLU가 효과가 좋았을까?
sigmoid 함수의 경우 치역의 범위가 0<n<1 이기 때문에
chain rule로 계속 이어 나간다면 결과가 0으로 수렴할 수 밖에 없다. 그렇기 때문에 1보다 작아지지 않게 하기 위해서 ReLU를 적용하게 하면 높은 정확도를 얻을 수 있다고 한다. 아직은 단순히 직관적인 이야기로만 받아들여진다. 추후에 더 공부해보자

'머신 러닝 및 파이썬 > 딥러닝 기초 , 파이토치' 카테고리의 다른 글
| parameter 확인하는 법 (0) | 2021.01.03 |
|---|---|
| Tensor Manipulation (0) | 2021.01.03 |
| Linear Regression (0) | 2020.12.29 |
| Supervised Learning (0) | 2020.02.18 |